Once upon a time, I was sitting in front of my laptop with an IDE where hundreds of different Kubernetes manifests were opened and I was thinking: “how come I am in this moment? I need to add a new service, but to do it, I have to keep in my mind zillions of details and configure dozens of files instead promised by marketing ’little changes’”.
It wasn’t my first frustrating time: I have always been thinking that the current practice of how to set up an environment is slightly more complicated than needed for micro/small businesses especially for pet projects. Yes, even in pet-projects we want to have automatic TLS, backups, databases, security, and other useful stuff. The system should be scalable. While those reasons sound like the truth, it also feels like the IT road turned somewhere wrong.

Photo by Jaime Nugent on Unsplash
My first attempt to escape from the overloaded, bulky, heavy setups was the trusted-cgi project, where I followed the idea, that we shall not pay for what we are not using. It is a working approach but has some limits such as not very flexible deployment and complete denial of modern and industry standards of shipping in containers (though supported by manifest with docker run inside).
Disclaimer, after my first attempt I decided to invest in the local servers (self-hosting) instead of cloud hosting (except gateways), so all my next attempts were performed in less limited environments.
The second (and less public) attempt was to move environment setup complications to the deployment phase via Ansible. The idea was: “I will write this boring and complex playbook once and for all”. While this approach worked quite well for several years, I ended up with hundreds of roles, playbooks, and custom modules. The limitations of Ansible playbooks (specifically conditions and exceptions) even made me look into Fabric for a minute.
The third attempt was to use lightweight Kubernetes builds like K3S. Honestly, this approach worked surprisingly well and was stable. Problems started when I wanted to set up persistent (stateful) applications with regular backups. The standard approach here is to delegate persistent volumes and backups/restores to the provider side. However, for self-hosting it was a huge mess. The solution was daily whole VMs (I used Proxmox) backup to somewhere else. While it did solve the problem, it also caused a huge unnecessary storage overhead. The last and less understandable point of Kubernetes - it does require maintenance. A lot of articles from people much smarter and more experienced than me may have different perceptions of the right use case for the Kuberentes, but they will share the same point on self-hosting K8S: do not manage Kubernetes by yourself unless there is an absolute need for this.
Given all of this, I decided to make a fourth attempt.
The idea
First of all, let’s split users into three different groups:
solo/micro/small business
- few (<7) number of nodes, all nodes may have very different specs and networks
- downtime is acceptable for a reasonable period (no need for HA)
- data can fit one server (no sharding)
- data loss between regular backups is acceptable
I would like to add one point: for the sake of cost optimization, it should be easy to move the environment from one node to another.
medium business
- significant (<100) number of nodes, usually single provider, single network, similar specs (or group of specs) for all nodes
- small downtime is still acceptable
- data may not fit one server
- data loss is unacceptable
big business
- large (>100) number of nodes, usually single provider, few groups of networks, similar specs (or group of specs) for all nodes
- downtime is unacceptable
- data not fit one server
- data loss is unacceptable
The gap between big and small businesses is so big, so my original attempts were based on a fundamentally wrong assumption that there is only one solution that fits all cases.
In reality, it’s barely possible to use enterprise solutions in medium companies or solo projects, because resource (humans, money) overhead will make no sense. At least two (let’s not forget about bus-factor) full-time, highly qualified engineers with expertise in Cloud Computing probably will consume all profit. From a DevOps perspective, Ansible/bash is king here.
A bit more interesting situation appeared in medium businesses: there are resources to maintain their infrastructure, but it could be too costly for managed services. In DevOps, Ansible/Swarm/light-weight Kubernetes setups rule here.
For huge enterprises, head cost plays less role, but maintaining their infra pool could be so complicated, so it usually makes sense to keep a reasonably small internal infrastructure team and outsource most of the headache to managed solutions. Cloud Kubernetes/Terraform dominates here.
These companies split into these groups based on my personal experience; however, don’t think about it as a strict rule. There are big corporations that are completely denying Kubernetes/Dockers (with a good reason though), as well as, I know micro companies built on top of GKS. The mileage may vary, but there is a correlation.
Portable stack
For my next attempt, I decided to focus on my case, which is solo/micro.
What I need is some kind of “portable stack”: a bundle with services and data, which can be relatively easily moved between servers. One day, you are using the free tier in AWS, the next day GKE, on Friday Oracle Cloud, and finally, settle in the home lab.
- For computing, we can use
dockertogether withdocker compose. Containers can give us the required portability and low overhead. - For data, as soon as we agree with data loss between backups, we can use any cloud non-structured storage system (ie S3). However, the backup MUST be client-side encrypted, with notifications in case of failure. I found
restica very good option for this.
a little bit more
- For traffic routing and TLS:
traefik,caddy,nginxwithcertbot - For authorization:
keycloak,authentik, free tier in Auth0 together withoauth2-proxy
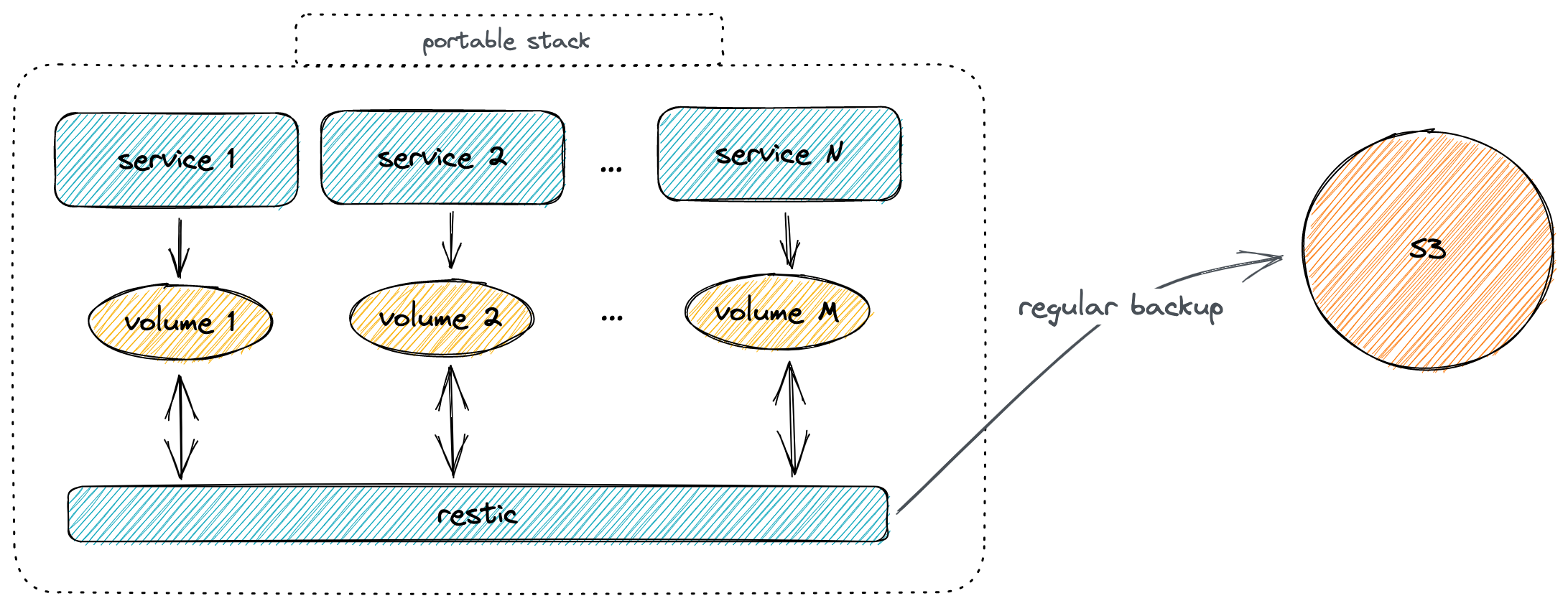
We can define a “universal” Ansible playbook for the deployments.
The sequence during the deployment on the new node should be:
- install the docker and docker-compose plugin
- upload compose file
- restore the backup if a backup exists and restore required
- start compose
- periodically backup data
draft compose file
services:
app: # any stateful application
image: "postgres:14"
environment:
POSTGRES_PASSWORD: postgres
volumes:
- app-data:/var/lib/postgresql/data
restic:
image: restic/restic:0.15.0
restart: "no"
command:
- backup
- /backup
environment:
RESTIC_REPOSITORY: "s3:https://${S3_ENDPOINT}/${S3_BUCKET}/${S3_PREFIX}"
RESTIC_PASSWORD: "${S3_ENCRYPTION_KEY}"
AWS_ACCESS_KEY_ID: "${S3_KEY_ID}"
AWS_SECRET_ACCESS_KEY: "${S3_KEY_SECRET}"
AWS_DEFAULT_REGION: us-west-000
volumes:
- app-data:/backup/app-data
volumes:
app-data: {}
ansible playbook
- hosts: all
vars:
SRCDIR: deployment
WORKDIR: /data
S3_ENDPOINT: s3.us-west-000.backblazeb2.com
S3_BUCKET: "..."
S3_PREFIX: "..."
S3_ENCRYPTION_KEY: "..."
S3_KEY_ID: "..."
S3_KEY_SECRET: "..."
tasks:
# install docker
- name: Install required system packages
apt:
update_cache: yes
state: present
name:
- 'apt-transport-https'
- 'ca-certificates'
- 'curl'
- python3-docker
- name: Add Docker GPG apt Key
apt_key:
url: https://download.docker.com/linux/ubuntu/gpg
state: present
- name: Add Docker Repository
apt_repository:
repo: "deb https://download.docker.com/linux/ubuntu {{ansible_distribution_release}} stable"
state: present
- name: Update apt and install docker-ce
apt:
name:
- docker-ce
- docker-compose-plugin
update_cache: yes
state: latest
# copy content
- name: Create work dir
file:
path: "{{WORKDIR}}"
state: directory
- name: Copy content
synchronize:
src: "{{SRCDIR}}"
dest: "{{WORKDIR}}/"
# restore if possible and needed
- name: Stop docker-compose
command: docker compose stop
args:
chdir: "{{WORKDIR}}"
- name: Init repo
command: docker compose run --rm restic init
args:
chdir: "{{WORKDIR}}"
environment:
S3_ENDPOINT: "{{S3_ENDPOINT}}"
S3_BUCKET: "{{S3_BUCKET}}"
S3_KEY_ID: "{{S3_KEY_ID}}"
S3_KEY_SECRET: "{{S3_KEY_SECRET}}"
S3_PREFIX: "{{S3_PREFIX}}"
S3_ENCRYPTION_KEY: "{{S3_ENCRYPTION_KEY}}"
register: init_backup
failed_when: "init_backup.rc !=0 and 'already initialized' not in init_backup.stderr"
- name: Check if restored
stat:
path: "{{WORKDIR}}/.restored"
register: restored_backup
- name: Restore
command: docker compose run --rm restic restore latest --target /
args:
chdir: "{{WORKDIR}}"
environment:
S3_ENDPOINT: "{{S3_ENDPOINT}}"
S3_BUCKET: "{{S3_BUCKET}}"
S3_KEY_ID: "{{S3_KEY_ID}}"
S3_KEY_SECRET: "{{S3_KEY_SECRET}}"
S3_PREFIX: "{{S3_PREFIX}}"
S3_ENCRYPTION_KEY: "{{S3_ENCRYPTION_KEY}}"
register: restore_backup
when: init_backup.rc !=0 and not restored_backup.stat.exists
failed_when: restore_backup.rc !=0 and 'no snapshot found' not in restore_backup.stderr
- name: Mark as restored
file:
path: "{{WORKDIR}}/.restored"
state: touch
# start everything
- name: Start docker-compose
command: docker compose up --remove-orphans -d
args:
chdir: "{{WORKDIR}}"
environment:
S3_ENDPOINT: "{{S3_ENDPOINT}}"
S3_BUCKET: "{{S3_BUCKET}}"
S3_KEY_ID: "{{S3_KEY_ID}}"
S3_KEY_SECRET: "{{S3_KEY_SECRET}}"
S3_PREFIX: "{{S3_PREFIX}}"
S3_ENCRYPTION_KEY: "{{S3_ENCRYPTION_KEY}}"
For those who are not familiar with Ansible let me explain what’s going on here:
- install docker from the official repositories
- stop all running services
- initialize backup repository and ignore an error if the repository already initialized
- check if this node has already restored
- if not restored yet, restore the backup and ignore an error if there are no backups yet
- mark the node as restored
- start all services
It means that regardless of how many times we will run this playbook, we will have consistent results. Also the migration to another node (even fresh) means just changing the host address in the inventory and all data will be automatically migrated through backup.
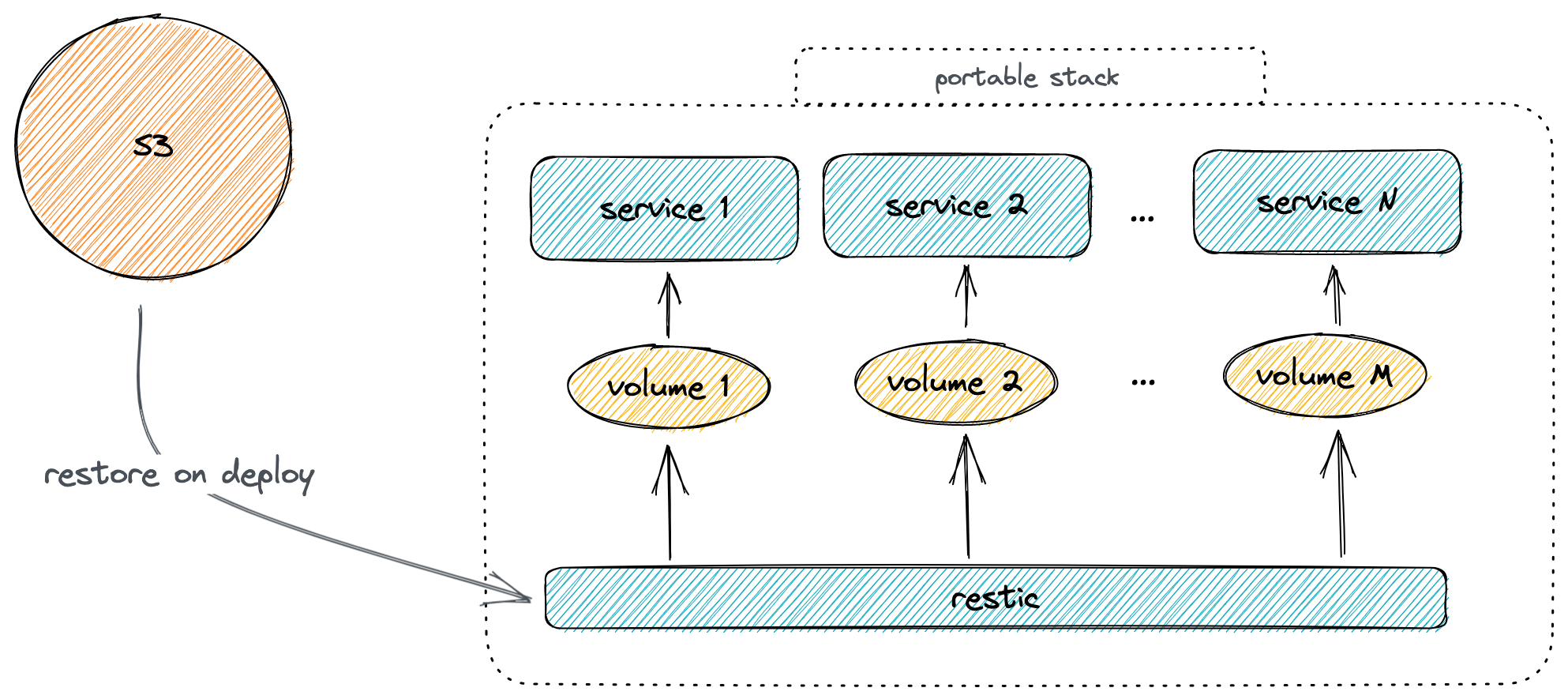
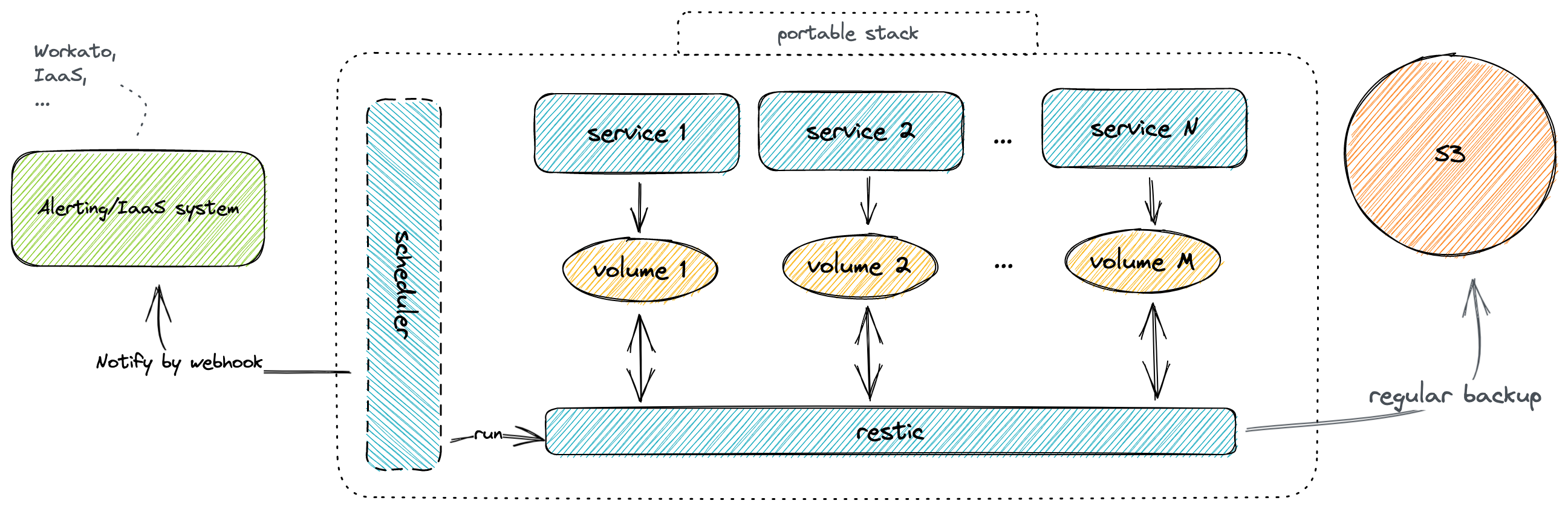
However, the problem is that restic will backup everything only once during the launch, and we probably want to have backups on a regualr basis. It also will be nice to have some kind of notifications after each backup.
The first thing that may come to mind is to use cron and invoke docker compose run restic each time. Unfortunatley, it means that configuration becomes scattered and harder to maintain.
To narrow down the problem, we want something like docker/docker-compose native scheduler. I found a very nice project Ofelia which can do exactly what we need, but unfortunately it can not respect compose namespaces and therefore it could cause a conflict between multiple docker-compose installations.
As an alternative, I created a compose-scheduler
which basically can run services or commands in services within the same compose file with HTTP notifications.
The main features of the service are zero-configuration by-default, designed for docker compose (auto-detect, respects namespace), and with HTTP notifications.
Let’s rewrite our compose file and add regular backups.
draft compose file with regular backup
services:
app: # any stateful application
image: "postgres:14"
environment:
POSTGRES_PASSWORD: postgres
volumes:
- app-data:/var/lib/postgresql/data
restic:
image: restic/restic:0.15.0
restart: "no"
command:
- backup
- /backup
environment:
RESTIC_REPOSITORY: "s3:https://${S3_ENDPOINT}/${S3_BUCKET}/${S3_PREFIX}"
RESTIC_PASSWORD: "${S3_ENCRYPTION_KEY}"
AWS_ACCESS_KEY_ID: "${S3_KEY_ID}"
AWS_SECRET_ACCESS_KEY: "${S3_KEY_SECRET}"
AWS_DEFAULT_REGION: us-west-000
volumes:
- app-data:/backup/app-data
labels:
- "net.reddec.scheduler.cron=@hourly"
scheduler:
image: ghcr.io/reddec/compose-scheduler:1.0.0
restart: unless-stopped
volumes:
- /var/run/docker.sock:/var/run/docker.sock:ro
volumes:
app-data: {}
Here:
- we added
schedulerservice which will scan for labels in the same compose project - we added
net.reddec.scheduler.cron=@hourlylabel which tells the scheduler to run this service every hour (uses Cron notation from robigfig/cron )
Sounds good, right? But we also want to have notifications in case our backup fails.
As a notification reciever, I will use Workato.
how to setup notification in Workato
Disclaimer: at the moment of writing this article I’m a FTE in Workato, so please do not judge me too much if I will be bias towards our solution. However, this is not a marketing article; it’s just happen that solution we built is an excellent fit for this (and many others) use-case.
final compose file with regular backup
services:
app: # any stateful application
image: "postgres:14"
environment:
POSTGRES_PASSWORD: postgres
volumes:
- app-data:/var/lib/postgresql/data
restic:
image: restic/restic:0.15.0
restart: "no"
command:
- backup
- /backup
environment:
RESTIC_REPOSITORY: "s3:https://${S3_ENDPOINT}/${S3_BUCKET}/${S3_PREFIX}"
RESTIC_PASSWORD: "${S3_ENCRYPTION_KEY}"
AWS_ACCESS_KEY_ID: "${S3_KEY_ID}"
AWS_SECRET_ACCESS_KEY: "${S3_KEY_SECRET}"
AWS_DEFAULT_REGION: us-west-000
volumes:
- app-data:/backup/app-data
labels:
- "net.reddec.scheduler.cron=@hourly"
scheduler:
image: ghcr.io/reddec/compose-scheduler:1.0.0
restart: unless-stopped
environment:
NOTIFY_URL: "https://webhooks.sg.workato.com/webhooks/rest/d17cefc7-44de-42a6-bacf-e6c923c8562a/on-backup"
volumes:
- /var/run/docker.sock:/var/run/docker.sock:ro
volumes:
app-data: {}
Scheduler will send notifications after each job if NOTIFY_URL env variable set. HTTP method, attempts number, and interval between attempts can be configured. Authorization via Authorization header is also supported.
Scheduler will stop retrying if at least one of the following criteria is met:
- reached maximum number of attempts
- server returned any 2xx code (ex: 200, 201, …)
Voilà!
We have our portable stack, which we can deploy anywhere with docker support, migrate data between nodes hassle-free, that’s without Kubernetes-like overhead, and is a transparent and clear system.